

We needed a way to sort large files using a predictable amount of memory. Big data technologies like map reduce were overkill for our data scale. Creating an offline-sort gem to do this turned out to be quite the adventure and forced me to dig deeper into how Ruby manages memory, ultimately requiring a specialized heap implementation.
Enter the Offline Sort
We can control memory usage during the sorting process by following a few simple principles. First, we never want to read the input file fully into memory. Instead, we must read data from the input in a streaming manner. As you can imagine, it’s not possible to fully sort the data when you never have access to all of the data at one time – so how are we going to achieve a sorted result? The typical approach is a form of merge sort that we refer to as an offline or external sort.
Here is the general idea: processing the input data as a stream, we partition it into chunks, sort each chunk, and write it out to a file on disk. At the end of this process we should have total_items/chunk_size intermediate chunk files. Next we open the chunk files and read one item from each file into a sorted collection such as a heap or a priority queue (often implemented using an underlying heap). This data structure will contain at most one item from each chunk file at a time. A heap is ideal for this purpose because it is simple to extract the minimum element. Whenever we extract an element from the heap we must be sure to add the next element from the same chunk file back into the heap. In this way, we can continually extract the lowest element from the heap and emit it to its final destination, usually the final sorted file.
The following image illustrates the merge phase of the process.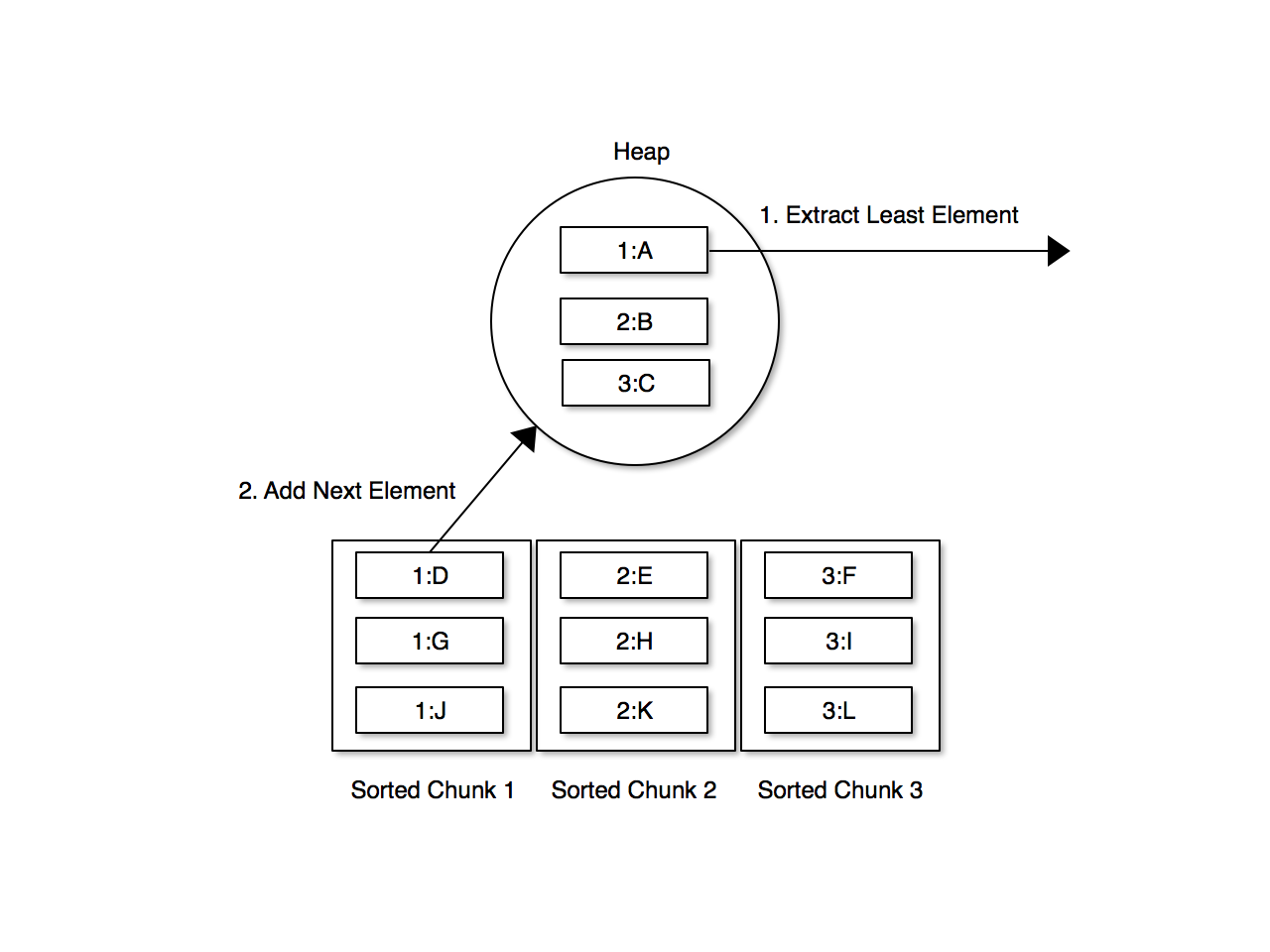
Off-the-Shelf Sort Options
Since memory controlled sorting is a fairly common problem, our first attempt was to find a gem to do the work. We found a single gem but upon reading the code we decided we could not rely on the gem for our purposes. The gem was neither widely used nor actively maintained, but more importantly the gem spawned processes for sorting the chunks as well as the final merge and managed these processes with threads. Although this has the benefit of ensuring that any memory used by these processes is completely returned to the system we felt that the extra complexity and start-up overhead were not appropriate for our case. In many cases we are running multiple worker processes on the same machine. If each of these spawned number_of_chunk_files + 1 ruby processes to run a sort operation the final result could be an explosion of ruby processes on the machine. The final issue we encountered was that the gem provided the ability to sort by certain columns of a CSV but did not fully support the CSV specification so embedded column separators were not handled properly.
Given these limitations we also briefly investigated using the Unix sort command. This utility allows you to sort a delimited file by a given column or columns. It supports merging sorted files so you can partition the data, sort it, and merge the results together. It even allows us to limit memory usage on some platforms. The problem again was that the sort command's concept of column separators is very rudimentary and does not meet our needs.
Salsify's Own Offline sort gem
After these two initial investigations I decided to write my own offline sort and to package it as a gem. The gem needed to have the following characteristics:
- The ability to sort any type of data by any number of properties. We sort CSV::Rows, arrays and hashes but it shouldn't matter to the gem.
- A simple form factor. Users should be able to call sort passing an enumerable for the input and a block to sort by and receive an enumerator which allows them to read sorted results.
- Pluggable serialization format. It should be possible to use formats like Ruby's Marshal, MessagePack, YAML or JSON for the chunk files. The serialization format will affect the speed of serialization and deserialization, memory usage, and the size of the chunk files and thus the amount of data to be read or written.
- Configurable chunk size. Specifically, the number of items per chunk should be configurable. Since chunks are sorted in-memory larger chunks will result in higher memory usage but a faster sort. Smaller chunks will better control memory at the cost of a slower sort.
Implementing the Gem
The implementation of the gem followed the basic pattern of an offline sort described previously. Here are the steps in a bit more detail.
- The consumer calls sort and passes an enumerable for the input and a block to sort by.
- Split the input into chunks.
- Read from the input enumerable until the input is exhausted or the maximum number of entries per file is reached.
- Sort the entries and stream them out to a file using the configured serialization strategy.
- Repeat this process until we have partitioned all of the input into sorted chunk files.
- Start the merge.
- Wrap each chunk file in an enumerator that uses the configured serialization strategy to read elements from the file one at a time
- Insert the first (minimum according to the sort block) element from each file into a priority queue.
- Return an enumerator that reads the smallest element from the priority queue. After any element is removed, add the next entry from that element's associated chunk file to the priority queue.
- The caller can now read the sorted data from the enumerator and handle the results as they see fit, usually by writing the output to a file.
Here are the split and merge functions that are the heart of the gem and implement the functionality outlined above.
Chunk Serialization Formats
I created a Chunk::InputOutput framework and wrote implementations for Marshal, and MessagePack. Each one is a fairly simple class that wraps an IO and allows individual objects to be written or read from the IO. By default Marshal can handle any Ruby type but MessagePack only works with simple types plus arrays and hashes. The MessagePack strategy must be subclassed to work with Ruby CSV::Row objects instead of hashes but MessagePack's performance will be shown to be worth the effort.
Here is the base class for all InputOutput implementations
and here is the super-simple Marshal implementation.
The Sort Function
The sort itself is implemented as a module method that constructs an appropriate sorter object and runs the sort. The example below sorts hashes by their :a property.
The Sorter class accepts initializer arguments to choose the chunk file size (number of entries) and the chunk file IO strategy. The default IO strategy is Marshal but this is easily changed to the more efficient MessagePack. Simply install the gem and require 'msgpack'. Prior to calling sort. You can also specify a strategy explicitly using the chunk_input_output_class named parameter.
Here is an example invoking the sort method with all of its parameters.
I wrote unit tests for the sorting algorithm and the serialization, then proceeded to write this blog post. Until...
Amazing (...ly bad) Performance!
Except for some performance testing early in the development process, I had been using relatively small input sizes to test the gem (on the order of 10,000 items). To facilitate the blog post I knew I needed memory usage numbers for various input sizes and serialization strategies so I needed to run some performance tests including much larger data sets. I found some unpleasant and surprising results. The library performed well with smaller data sets, as expected, but I noticed that increasing the size of the input file drastically degraded performance. In fact with 1 million items both running time and memory usage were unacceptably bad and with 5 million rows the test ran for hours without completing. During these large tests CPU usage was steady at 99% and memory sizes ballooned to several gigabytes - as much as, or more than, the amount of memory necessary to do a full in memory sort of the data.
What was going on? This is after all a fairly straightforward computer science problem and I was pretty sure I didn't make any obvious mistakes in the code. After reviewing the code to reassure myself that I wasn't loading the entire data set into memory mistakenly I began to systematically examine CPU and memory usage on various parts of the application.
I profiled different parts of the library. During this exercise, I used a great script from this post by Brian Hempel. I also enabled the GC profiler to understand how frequently the runs occurred and how long they took. Some of the code was testable in the context of the gem but in other cases I needed to extract small parts of the code out into standalone Ruby programs in order to isolate and measure them. The experiments that I performed were:
- Round-tripping the input data to an output file and back to test the overhead of the serialization strategies. As expected I found that there were differences in the speed and memory overhead of Marshal vs MessagePack but these not were serious contributors to the behavior I was seeing.
- Using hard-coded sorts rather than an arbitrarily complex block for sorting. This had a negligible effect on performance.
- Putting several items into the priority queue used for merging the chunk files and then successively popping an item and pushing a new one hundreds of thousands of times.
BINGO! Performing this final operation had exactly the effect I had witnessed. CPU stayed maxed out for the entire test run and memory ballooned to over 3GB. At this point in the development process I was using a priority queue rather than a simple heap. Keep in mind that during this test, I was not allowing the priority queue to grow. The priority queue for the offline sort library will have at most a number of elements equal to the number of chunk files and, in my tests, I was being careful to use between 10 and 50 chunk files at all times.
Ruby Heap Implementations
My next stop was the source code for the priority queue. I could immediately see that the process of adding and removing from the queue was resulting in a proliferation of array objects. I was still surprised it was putting that much pressure on the running application so I ran again with the garbage collector profiling enabled. The results showed a shocking amount of time being spent in garbage collection throughout the lifetime of the test and a very low level of reclaimed objects from each run.
Rather than spending too much time understanding the priority queue implementation I decided to try some alternatives. I tried the min heap implementation from the ruby algorithms gem as well as a new priority queue suggested by a contributor to the original priority queue gem . Despite very different implementations each of these libraries produced similarly large numbers of allocations causing high levels of memory usage and GC thrashing.
A Special Purpose Heap
At this point I reasoned I could do as well or better myself, so I built a heap specialized for my use case i.e. a heap that will never be more than n elements. Because my heap will never grow, it can be ordered in-place. It can also take advantage of the fact that after an initial ordering of the data you are only going to add or remove one element at a time.
The implementation is simple. An input array is heap ordered in place. There are two operations on the heap. A pop operation removes the minimum element from the heap and shrinks it by moving an internal pointer. A push operation grows the heap (but not beyond its initial capacity) by moving the pointer, inserts the new element and re-establishes the heap. The size of the underlying array never changes. This specialized heap is faster and never allocates new arrays or copies elements, other than swapping references during re-heaping, so it has desirable memory characteristics.
My offline sort gem now had predictable memory characteristics and reasonable speed meeting the goals of the exercise.
I tested the sort with a 5 million element input file using chunks of 100 thousand elements each. The total data size of the input on disk was 440MB serialized using Marshal. Each element in the file was a 3 element array consisting of two strings and a number. Here are some results sorting the data with with the new heap implementation. Note that the running time includes the time to read the data from disk and load the objects but that is indicative of real world usage.
MessagePack chunk file serialization
56.14 seconds
77 GC runs
265MB peak memory usage
Marshal chunk file serialization
340.62 seconds
865 GC runs
140MB
As you can see MessagePack is the clear winner but memory is well controlled in both cases.
Conclusion
I have several recommendations to offer after the experience of developing this gem.
- This should go without saying, but when you are working on a project that is performance focused you must establish a performance test framework and use it early and often. If I hadn't performance tested in preparation for this blog post, the poor performance of large data sets would have surfaced in production.
- With languages like Ruby, attempting to manage memory by streaming data to and from files is necessary but not sufficient. In my case, the sheer number of ephemeral objects created for moderately large data sets was enough to make both performance and memory usage worse than a full in-memory sort.
- Write modular code so different parts of the solution can be easily isolated and performance tested. Be ready to extract parts of the code in order to isolate them for performance testing when it is not possible to test them in-place.